Last week I’ve been at the QAI Quest Testing Show in Toronto, ON. Having a long history in the testing business myself it was interesting to talk with Manual and Functional Testers. We discussed their processes and the tools that they use and how their day-to-day life looks like when interacting with developers about issues that were discovered by their testing efforts.
Whats the typical process when an issues is identified?
Once an issue has been identified – either through a manual test or through an automated functional test – the developer needs to be notified about it. The following steps briefly outline the typical actions:
- Tester: Create a new ticket in your bug tracking system
- Tester: Describe each step that led to the error
- Tester: Attach screenshots that show the problematic part of the application
- Tester: Attach additional application and system log files
- Developer: Follow the described steps to reproduce the problem
- Developer: Request additional information if the problem is not reproducable or if log information is missing
- Tester: Providing additional information
- Developer: Fix the problem
- Tester: Re-test and verify the issue
What are the problems with this process?
The main problems with that process is that
- Testers have to spend a lot of time to create issue descriptions and collect all the necessary information
- Developers need to reproduce the problem on their local environment
- Issues often cycle between Testers and Developers in case issue is not reproducable – lots of time is wasted with this “Ping/Pong” game
How to fix the process?
In order to solve these problems we need a mechanism to automatically capture all the information that is needed by the developers so that testers dont have to collect all the information. The captured information must also not only include the sympton description and how to get there – but must also include the actual problem that happened so that developers dont need to reproduce the problem.
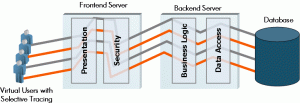
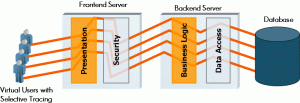
Using a solution like dynaTrace – when executing a manual or functional tests – enables Testers to automatically capture code-level information on the application that is tested for those test steps that actually fail. The captured PurePath includes all information that a developer needs to analyze the problem without having to reproduce it because the PurePath shows the exact problem in the application code in the context of the executed test steps.
Therefore – capturing PurePaths for the executed tests eliminate documentation of the issues as well as the reproduction efforts. It also eliminates the “Ping/Pong” game as the PurePath contains all the contextual information a Developers needs in order to analyze the problem.
Conclusion
Too much time is spent between Testers and Developers to work on issues that have been identified. With the correct solutions in place we can minimize all the tedious work or manual issues documentation and problem reproduction. Capturing diagnostics information on the tested application provides all the information for Developers to analyze and fix the problem without having to request additional information and without reproducing the problem. It saves a lot of time and overhead and frees your valueable resources to do the work they should really do.